When APIs and source code are made openly available, magic can start to happen. If one wanted to plumb the inner workings of Zotero, the bibliographic and research software from the Roy Rosenzweig Centre for History and New Media, it is simply a matter of copying all of the code from https://github.com/zotero/zotero. (There are a variety of ways to do this, which we’ll go over in our discussion of why and how you might use ‘versioning control’. At the very least, from that webpage, you can download the source code with a single click of the ‘download as zip’ button). Once you have a copy of the source code, you can look inside and build new functionality. Very few people are ever going to need to do this, but this openness allows for Zotero’s capabilities to be expanded drastically. This is what Jo Guldi and Chris Johnson-Roberson did, to build a new tool called ‘Paper Machines’, as a plug-in or add-on for Zotero. (The code for this plugin is also open source, and may be found at https://github.com/chrisjr/papermachines . Note that it is itself is built on a number of other open source software packages. When code is made available for reuse, sharing, and extension, the gains increase exponentially!).
To install Paper Machines on your computer (and assuming you’ve already installed and use Zotero to manage your online research), go to http://papermachines.org and follow the instructions on the download page. Paper Machines allows the researcher to produce some quite sophisticated visualizations of the materials in her Zotero library with only a few mouse clicks. If for instance you had collected together a corpus of materials from JSTOR, Paper Machines will extract the text from those pdfs and together with the bibliographic meta data provide “iterative, time-dependent visualizations of what a hand-curated body of texts talks about and how it changes over time”. That is, it will extract and highlight different trends in your corpus of materials.
This also can work on museum collections, online database, or any of the other resources that Zotero can be used to curate. For instance, say that you are interested in the diaries of John Adams (1735 – 1826). The Massachusetts Historical Society has transcribed these diaries and has put them online at http://www.masshist.org/digitaladams/aea/diary/index.html. If you go to the ‘browse’ section of this site, you can obtain a linked list of all of the diaries arranged by date. Each page has multiple entries, sometimes spanning only a few months, sometimes over a year.
Some complicated webscraping could extract each diary entry off each page. ((A program such as Outwit Hub can do it fairly easily; it is a plug-in for the Firefox browser. Its free edition can scrape 100 rows of data. It allows you to examine the source html of a page, discover which html or xml tags bracket the information you are interested in, and grab that particular data)) There are no embedded metadata on these subpages that Zotero understands. With the Zotero pane open in your browser, you can still create a record that can be usefully parsed by Paper Machines. Click the page icon in zotero (“create web page item from current page”). In the Information tab, Zotero will automatically put the title of the page, the URL, and the date accessed. In the ‘date’ field, you can enter the date(s) associated with the page. Sometimes this might be a range: “18 November 1755 – 29 August 1756”, other times a series of dates or ranges: “June 1753 – April 1754, September 1758 – January 1759”. Save ten or so pages into your zotero library, and add appropriate date information.
Right-click the folder icon for your collection and select, “extract text for paper machines”. Follow the prompts. When Paper Machines has finished extracting your text, the other options on the right-click contextual menu (the menu that pops up when you right-click the folder) are now available to you. Select ‘topic modeling’ and then ‘By time…’ and set whatever other settings strike you as important (such as changing the default number of topics). Paper Machines ‘stems’ the words that it finds, so that ‘constitution’ and ‘constitutional’ are parsed back to a common root, ‘constitut’ (this option can be switched off).
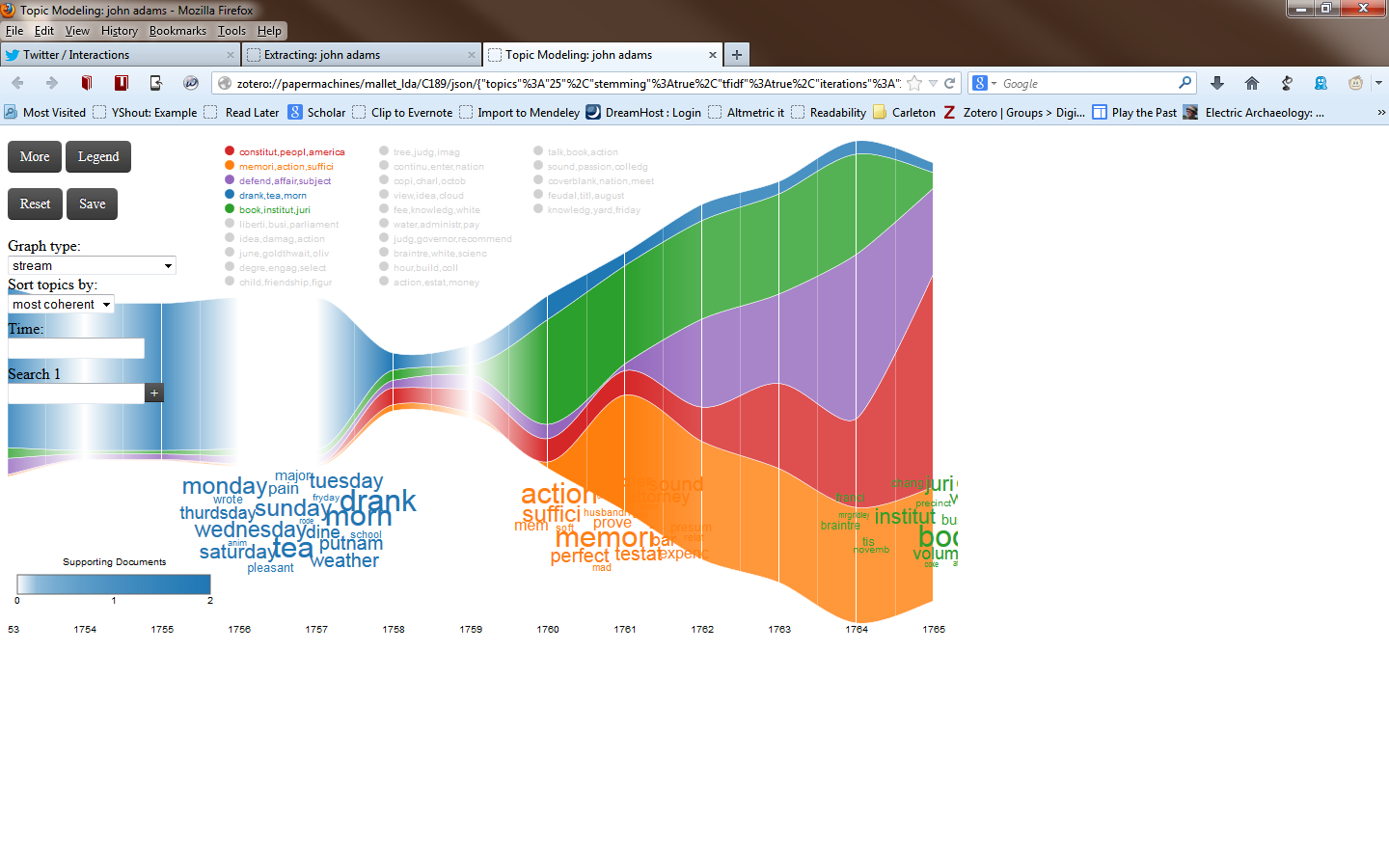
If all goes well, after a few minutes, you will be presented with a ‘stream graph’ of the topics determined for this particular corpus as in the image below. In that figure, we topic modeled the first 13 pages by date from the Massachusetts Historical Society’s site. A stream graph visualizes the changes in topic distributions over time. Paper Machines allows one to resort the graph by ‘most coherent topics’, ‘most common’, and ‘most variable’. In Figure xxx, one can immediately see that as a younger man, John Adam’s thoughts centred most around discussions of his daily mundane life, with a slight current of discourse surrounding his law practice and perhaps his intellectual musings. The short biography of Adams provided by the Historical Society describes his journals and points to the year 1774 and Adams’ involvement with the Continental Congress as a major change in the contents of his diaries. However, it is quite clear in the stream graph that a topic related to ‘constitution, people, america’ grows stronger from the late 1750s onwards, increasing markedly in importance to the end of the entries we have modeled.
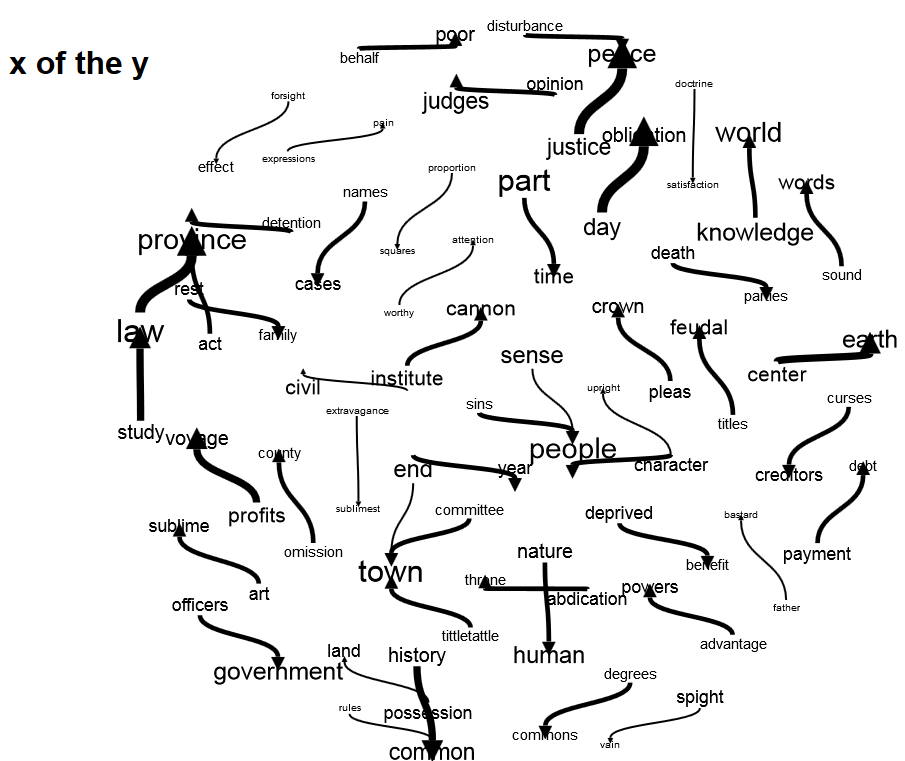
Other interesting outputs from Paper Machines include multiple word clouds and geographic heat maps or ‘flight paths’. Paper Machines can parse the text for place names, and create ‘hot spots’ for the places most mentioned in the map, or link in sequence places as they appear in the map. N-grams (that is, phrases of varying lengths) can also be displayed. Phrase nets give a sense of the way discourses play out through the entire corpus. The image below is a phrase net ‘x of the y’ in these diaries. The direction of the arrow indicates how to read the connection, and the thickness of the arrow indicates the relative frequency that the phrase appears. All of these tools are not about justifying a particular conclusion about the corpus, but are about generating new insights, of transforming what we see through the deformations (topic models, phrase networks). ‘Study -> law’ is ‘study of the law’ and the width of that arrow shows us that it is a frequent contributor to the corpus. ‘Law’ connects onwards to ‘province’ as does ‘act’, thus that entire phrase net seems to tie into Adam’s practice. Another net ties ‘character -> people’, ‘sins -> people’, ‘sense -> people’, and ‘character -> upright’. Is Adams concerned that ‘the people’ are not being best governed, or are bringing these trials and tribulations upon themselves?
We are now reading the corpus distantly, in order to get a sense of the macroscopic patterns it contains and to generate new questions with which to approach the corpus. Historian Adam Crymble recently conducted an experiment where he asked experts on the criminal trials recounted in the Old Bailey Online to look at word cloud visualizations of the transcript of a trial. Word clouds, remember, are simply frequency histograms rearranged to size the words relative to their frequency. Could the experts reconstruct what happened from this distant reading? Crymble had a trial selected at random and visualized as a word cloud (Crymble did not know which trial). Then Crymble and four others tried to put together what the trial was about. He concludes that three of the five did a very good job of reconstructing the events if they stayed away from trying to provide an excessive level of detail (those who constructed a detailed story from the word cloud engaged in too much guesswork). Crymble writes,
I think the secret is in moving away from the idea that tokens transmit ideas. Ideas and metaphors transmit ideas, and it would be far more useful to have an idea or concept cloud than one that focuses on individual tokens. But I also think it’s time that those ideas were linked back to the original data points, so that people interpreting the word clouds can test their assumptions. We are ready to see the distance between the underlying data and the visualization contracted. We’re ready to see the proof embedded in the graph.((http://adamcrymble.blogspot.co.uk/2013/08/can-we-reconstruct-text-from-wordcloud.html))
This takes us back to the question of what ‘topics’ and ‘bags of words’ really are. The tokens, the individual lemmatized (or not) words, may at first appear to be coherent ‘topics’ as one might understand from a catalogue, but their original contexts have become blurred. As far as using topic models, word clouds, and phrase nets for historical analysis we have to be leery of using them to create detailed stories. Think of them as streams, as associations, as generative direction finders, instead.